Динамический анализ среды функционирования в оценке эффективности научно-исследовательского сектора российских регионов


Ключевые слова
Аннотация
Анализ среды функционирования является одним из широко распространенных непараметрических методов сравнительной оценки эффективности. Среди многочисленных модификаций метода в последнее время основное внимание исследователей уделяется динамическим вариантам данного анализа. В настоящей статье мы используем динамический анализ для оценки эффективности научно-исследовательского сектора российских регионов. В качестве традиционных переменных входа используются численность научно-исследовательского персонала и затраты на исследования и разработки, а в качестве переменных выхода — публикационная и патентная активность. Для оценки динамики изменения показателей рассматривается достаточно длительный период с 2009 по 2020 г. Особенностью предлагаемой оценки является использование показателя качества публикационной активности как «переходящей» переменной (carry-over variable) наряду с накопленными затратами на исследования и разработки. В статье проводится сравнение результатов с более ранними оценками научно-технологической сферы российских регионов на основе анализа среды функционирования. Показано, что предлагаемая методика является полезным методом ранжирования, который дополняет имеющиеся оценки научно-технического потенциала регионов с точки зрения эффективности. Осуждаются перспективы и ограничения использования метода для оценки и прогнозирования научно-технологического облика регионов.
Введение
Анализ среды функционирования (АСФ, или метод DEA — Data Envelopment Analysis) представляет широкий класс непараметрических методов, которые часто применяются для ранжирования объектов наблюдений по их производственной эффективности [1], [2], [3]. Емкий обзор современных разновидностей DEA приводится, например, Ч. Kao [4]. Несмотря на широкую известность, метод продолжает развиваться, особенно в части динамических [5] и стохастических [6] приложений.
В российской научной литературе первые исследования, посвященные использованию метода DEA, появились в конце XX — начале XXI в. В работах отечественных авторов метод получил русскоязычное название «анализ среды функционирования (АСФ)», или «технология анализа среды функционирования (технология АСФ)» [7], [8], [9]. Этот перевод прочно укрепился в научной среде, однако встречаются и другие интерпретации в отношении подхода к оценке сравнительной эффективности экономических объектов, например «DEA-анализ» или «метод DEA» [10], [11], [12], анализ свертки данных [13], [14], анализа охвата данных [15], анализ оболочки данных (АОД) [16], [17].
На наш взгляд, именно «анализ охвата данных» является наиболее точным переводом термина «data envelopment analysis» на русский язык, однако в рамках данного исследования авторы используют термин «анализ среды функционирования», соблюдая принцип преемственности.
DEA основан на универсальном понятии эффективности, под которой понимается отношение результативных выходов (outputs) к ресурсным входам (inputs) для некоторого объекта. При этом не предполагается какой-то функциональной зависимости между выходами и входами, что собственно и позволяет отнести метод к непараметрическим. Основным инструментом DEA является оптимизация. Суть метода заключается в том, что решается столько задач оптимизации, сколько есть объектов наблюдений; при этом целевая функция в том или ином виде отражает эффективность данного объекта (по очереди), а система ограничений включает данные обо всех наблюдаемых объектах [18]. Таким образом, все объекты получают оптимальную оценку своей эффективности на основе имеющихся данных. Это позволяет сравнивать объекты между собой (ранжировать) на основе их способности трансформировать ресурсы в результаты.
Важное достоинство DEA — возможность включения в анализ одновременно нескольких выходов, причем с различным масштабом и единицами измерения. Это объясняет универсальность DEA: выбор объектов исследования (например, регионов) задает дисциплинарную область, а выбор ресурсов и результатов деятельности (например, научно-исследовательская сфера) формирует предметную область анализа.
Цель настоящего исследования — построение нового типа ранжирования научно-исследовательской деятельности регионов на основе сравнительной оценки эффективности методом динамического DEA.
Метод DEA получил широкое распространение в региональных исследованиях, так как многофакторное сравнение регионов выступает постоянным исследовательским фронтом [19]. Также DEA часто используется для оценки технологического потенциала на уровне отраслей (industries) [20], [21]. Мы, вслед за многочисленными исследователями [22], [23], [34], [25], применяем DEA с целью оценки научно-технологической эффективности регионов. Причем две последние работы сделаны на материалах по российским регионам, что дает возможность для сравнения результатов.
Метод DEA рассматривается нами как один из подходов к оценке эффективности деятельности определенных объектов наравне с методами регрессионного анализа, индексного метода или анализа стохастической границы производственной функции. По результатам такой оценки, как правило, выдвигаются рекомендации по улучшению эффективности функционирования объектов и выявляются неэффективные объекты различных систем на макро-, мезо- и микроуровнях на основе построения так называемой «эффективной границы», которая определяется деятельностью наиболее эффективно функционирующих объектов из всей совокупности. Также метод может быть использован для анализа влияния различных территориальных факторов на соответствующие характеристики региональных систем, например для оценки эффективности функционирования региональной системы науки и образования [26], энергетической сферы [27], системы экологического менеджмента [28], инновационного производства [29]. Метод DEA не анализирует процессы внутри системы, однако позволяет анализировать входы и выходы и давать рекомендации по оптимизации этих показателей для повышения эффективности функционирования системы [30].
Использование метода DEA в целях изучения системы производства новых знаний позволит более взвешенно подходить к процессу принятия кадровых и финансовых решений на региональном уровне для обеспечения эффективного функционирования инновационной системы. Как было отмечено ранее, результатом использования метода DEA зачастую выступает анализ отклонений деятельности отдельных объектов от эффективной границы и выдвижение рекомендаций по повышению эффективности этих объектов. Так, С. В. Ратнер [31], применив метод задания цели, предлагает рассчитывать проекции неэффективных объектов региональных экономических систем в пространстве входов и выходов на границу эффективности, что позволяет определить целевые ориентиры по сокращению входов и увеличению выходов, достижение которых делает объект эффективным. При этом для оценки эффективности функционирования объектов в динамике авторы использовали метод «window analysis», который основан на выборе окна наблюдения для каждого производственного объекта определенной ширины, что обеспечивает робастность оценок эффективности и выявляет тренды в изменении эффективности объектов. В исследовании О. О. Комаревцевой [32] метод DEA был использован для оценки интенсивности взаимосвязи между финансовой и социальной эффективностью муниципальных образований Орловской области. Также методику можно применять как способ оценки эффективности деятельности предприятий с использованием финансовых показателей, которые описывают финансово-хозяйственную деятельность предприятий, а не объемы затрачиваемых ресурсов и выпусков [33]. Авторы отмечают, что метод DEA позволяет оценивать эффективность с разным набором ресурсов, а также ранжировать объекты по уровням эффективности, благодаря чему можно определять неэффективные объекты и давать рекомендации по повышению их эффективности.
Метод способствует выявлению состояния и динамики эффективности, которые не всегда связаны с объемом ресурсов и размером самих регионов. Ценность DEA заключается в том, что его результаты зачастую бросают вызов стереотипным представлениям о состоянии научно-технологической сферы в разрезе регионов. При этом к результатам анализа следует подходить критически, так как они связаны с качеством данных. Например, если региональная статистика систематически недоучитывает показатели затрат или численности персонала в конкретном регионе, то это может привести к ложной оценке его высокой эффективности.
В целом методологические проблемы DEA являются следствиями его достоинств. Во-первых, DEA весьма чувствителен к качеству данных (к выбросам, резким перепадам значений и т. п.). Во-вторых, для классических реализаций DEA не применим традиционный инструментарий статистической оценки получаемых результатов (хотя в литературе существуют подходы к этой проблеме, см., например, [6]). Поэтому при необходимости учета случайного характера оценки данных следует обращаться к альтернативным классам моделей, например к анализу стохастической границы производственных возможностей (Stochastic Frontier Analysis, SFA, см. [1], [34]).
Статья структурируется следующим образом. Сначала мы характеризуем используемую динамическую модель на основе исследования [22]. Затем следует описание данных о научно-исследовательской сфере1 российских регионов за период 2009—2020 гг. (при этом дополнительно используются показатели публикационной активности за 2021 г., показатели внутренних затрат на исследования и разработки за 2008 г., показатели патентной активности начиная с 2007 г.). Описываются критерии отсечения при формировании окончательной выборки регионов. В следующем разделе приводятся основные результаты расчетов и их визуализации, сравнения результатов с ранее полученными данными. Обсуждение результатов и основные выводы завершают исследование.
Модель динамического DEA
Основной целью использования DEA является оценка эффективности, под которой понимается отношение эффектов (результатов) к затратам ресурсов. В рамках DEA эффективность, как правило, принимает вид технической эффективности, то есть отношения оптимального объема необходимых ресурсов на единицу выпуска к фактически потраченным ресурсам (подробнее, см. [1]).
Оптимизационная задача в рамках DEA может быть представлена в виде прямой или двойственной задачи (соответственно, представление на основе огибающей (envelope) или на основе мультипликаторов). Мы используем динамическую модель [18], которая, в свою очередь, является модификацией модели «реляционного анализа» (relational analysis), предложенной в [18]. В традиции этих авторов использовать представление задачи на основе мультипликаторов, и мы будем ее придерживаться.
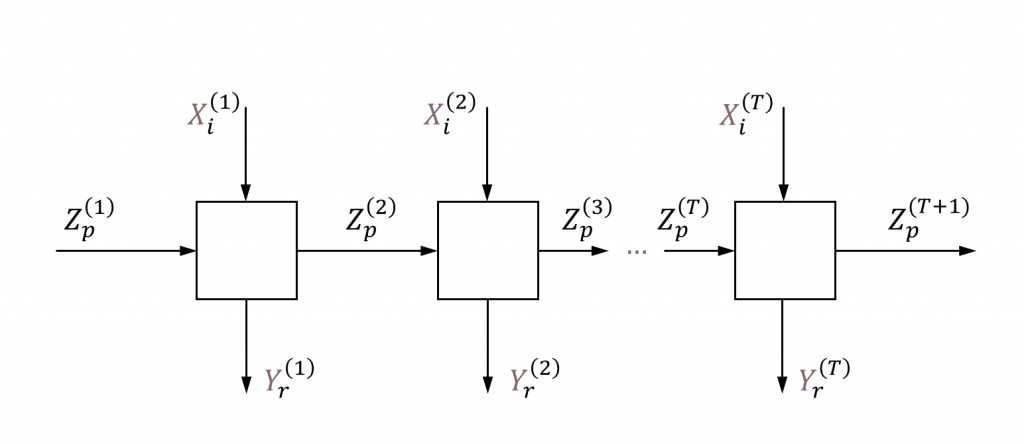
Итак, нам дано n объектов наблюдения (регионов), по которым собраны панельные данные за T периодов по трем группам переменных — выходов Yr, входов Xi и переходящих (между периодами) переменных, Zp. В контексте динамического DEA основного внимания заслуживают именно переходящие переменные Zp (рис. 1). Без них модель представляет собой простую совокупность из T статических моделей.

На приведенной схеме рассмотрено по одной переменной каждого типа для одного объекта наблюдения. Для реализации данной схемы для всех объектов необходимо собрать панельные данные, описание которых приводится в следующем разделе. Переходные переменные должны быть собраны за T + 1 период.
К сожалению, матричная запись не очень удобна для описания данной задачи, поэтому используется достаточно громоздкая индексная запись. В результате задачу максимизации индивидуальной эффективности можно сформулировать следующим образом:
Оптимизация происходит по положительным мультипликаторам ur, vi, wp, так как ε — это некоторая малая положительная величина. Забегая вперед, отметим, что в нашем случае будут рассматриваться 6 мультипликаторов — по 2 на каждую группу переменных. Поэтому в результате n оптимизаций будет сформировано n наборов из 6 мультипликаторов. Также обратим внимание, что мультипликаторы не меняются по периодам.
Видно, что максимальное значение целевой функции (первое выражение, Ek) — это и есть искомый показатель эффективности для некоторого объекта k из множества объектов n. От первой группы ограничений (n штук) выражение для целевой функции отличается только индексом j вместо k, где j = 1, 2, ..., n. Это означает, что мы решаем отдельную задачу для каждого объекта, принимая ограничения, что эффективность никакого из объектов рассматриваемой группы не превышает единицы2.
Наконец, есть вторая группа из n × T ограничений. Выражения для них отличаются от предыдущей группы тем, что убрано внешнее суммирование по T (в нашем случае таких ограничений, соответственно, будет 804 для каждого k).
Для более эффективного числового решения выражения в модели модифицируются таким образом, чтобы убрать громоздкие отношения (см. [18, p. 327]). Поскольку эффективность является отношением, то знаменатель можно нормировать к 1.
Обозначая числители и знаменатели из второй группы ограничений через B = ∑r=1urYrj + ∑p=1wpZpj и A =∑i=1vi Xij + ∑p=1wpZpj, упрощенную схему решаемой задачи можно представить так3:
В данном представлении суммирование происходит по T, и мы опускаем индексы для простоты. В приложении мы реализуем эту упрощенную схему на примере функционального кода на языке Wolfram.
Данные
Мы собрали данные по показателям, которые традиционно характеризуют научно-исследовательскую деятельность. Данные представлены в разрезе субъектов Российской Федерации за период 2008—2021 гг., но первый и последний периоды резервируются для усреднения показателей, связанных с исследовательской активностью, и для создания переходящих переменных. Таким образом, в модели T = 12 (период 2009—2020 гг.).
В качестве ресурсных показателей (входов) были использованы статистические данные, которые можно найти в ежегодных сборниках «Регионы России. Социально-экономические показатели»4:
1. Численность персонала, занятого научными исследованиями и разработками. Показатель включает различные категории персонала, а не только исследователей, поскольку это более подходит для целей оценки эффективности.
2. Внутренние затраты на научные исследования и разработки. Все оценки с помощью индекса потребительских цен по регионам приведены к показателям 2010 г.
Основные результирующие показатели (выходы):
1. Количество публикаций за период 2010—2021 гг. Показатель учитывает количество индексируемых в Scopus научных работ всех типов5. Следует обратить внимание, что показатель сдвинут на один период вперед. Это объясняется тем, что между периодом осуществления затрат и выходом публикаций проходит время, которое, по соглашению, составляет от 1 до 3 лет [35].
2. Количество поданных патентных заявок на изобретения. Показатель патентной активности в регионах России приводится по данным Роспатента6. Показатель усреднялся за три года, поскольку для него характерны резкие перепады по годам. При этом в отличие от учета публикаций мы принимаем допущение, что патентная заявка оформляется в период ее активной подготовки7.
В качестве источника библиометрических данных была выбрана база Scopus компании Elsevier. В метаданных публикаций содержится информация об аффилиации каждого автора статьи, что позволило распределить массив российских публикаций по регионам. Данные по публикациям были агрегированы для 78 регионов и городов федерального значения России8.
Для агрегирования был выбран метод полного подсчета [36]: публикация, написанная совместно авторами из нескольких регионов, засчитывается каждому из регионов в полной мере. Для этого потребовалось, во-первых, объединить публикации организаций, имеющих валидированный профиль в Scopus, в набор для каждого региона России; во-вторых, осуществить поиск публикаций организаций, не имеющих валидированного профиля в Scopus, и добавить их в соответствующие наборы для регионов.
Наконец в качестве переходных переменных в модели были использованы:
— накопленные затраты, сформированные на основе агрегирования долей внутренних затрат на научные исследования и разработки за период 2008—2020 гг.;
— показатель цитируемости, взвешенный по предметной области Scopus (Field-weighted citation impact, FWCI), публикаций за период 2009—2021 гг. Данный показатель рассчитывается как соотношение полученных цитирований к ожидаемому среднему мировому значению для предметной области, типа и года публикаций9. Если FWCI равен 1, это значит, что показатели цитируемости рассматриваемых работ полностью соответствуют ожидаемому глобальному среднему значению. Мы сглаживаем данный показатель за два последовательных периода.
В качестве переходных переменных в литературе рекомендуется использовать переменные, для которых характерно формирование запаса (stocks). Как правило, речь идет о запасах капитала. Известно, что статистику такого типа затруднительно собрать для научно-технологического сектора, поэтому возможным прокси-показателем является накопление части внутренних затрат по периодам [22]. В модели мы капитализируем ежегодно 5 % таких затрат на исследования и разработки10, а также применяем норму амортизации к накопленному показателю на уровне 20 % годовых.
Показатель цитируемости отражает один из аспектов качества публикационной активности. Мы исходим из того, что научная деятельность сопряжена с накоплением опыта, связанного с качеством результатов. Накопленное качество публикаций, с одной стороны, — результат научно-исследовательской деятельности, а с другой — ресурс на входе для создания новых научно-исследовательских результатов. Одним из показателей качества публикационной активности выступает FWCI. При этом показатель нормирован таким образом, что не требует логарифмирования.
Поскольку регионы сильно различаются по масштабам, представляется целесообразным логарифмировать основные переменные для получения сопоставимых рядов динамики. Несмотря на то что итоговые ранжирования между исходными и логарифмическими данными разные логарифмическое представление дает более ровную картину и меньшие отличия в разбросе эффективности по годам.
Сглаженные показатели и их символьные обозначения представлены на рисунке 2. Как видно, даже для такой ограниченной панели данных сделать выводы на основе исключительно визуальной оценки не представляется возможным. При этом мы имеем более одного показателя на выходе каждого периода в модели. В этой связи востребованы методы автоматической оценки, такие как динамический DEA, результаты применения которого будут представлены в следующем разделе.

Статистическая характеристика данных приведена в таблице 1.
|
Символ |
Среднее значение |
Стандартное отклонение |
Минимальное значение |
Квантиль 0,25 |
Медиана |
Квантиль 0,75 |
Максимальное значение |
|
X1 |
7,98 |
1,44 |
4,04 |
6,87 |
7,77 |
8,89 |
12,39 |
|
X2 |
7,54 |
1,59 |
3,82 |
6,38 |
7,36 |
8,57 |
12,32 |
|
Y1 |
5,95 |
1,45 |
2,64 |
4,97 |
5,83 |
6,74 |
11,09 |
|
Y2 |
5,08 |
1,16 |
1,92 |
4,30 |
5,05 |
5,78 |
9,25 |
|
Z1 |
5,69 |
1,59 |
1,69 |
4,51 |
5,49 |
6,72 |
10,61 |
|
Z2 |
0,61 |
0,35 |
0,08 |
0,41 |
0,57 |
0,72 |
3,77 |
Примечание: для переходных переменных взяты ряды с лагом.
Для итогового ранжирования из выборки были исключены регионы с характерными отклонениям в данных (например, те, у которых слишком низкая публикационная или патентная активность)11. Итоговое количество регионов составило n = 67.
Результаты анализа
В базовой постановке решение задачи оптимизации с помощью пакета Mathematica выдает показатели эффективности и соответствующее интегральное ранжирование, представленные в таблице 2. В столбцах 5 и 6 мы для сравнения приводим результаты ранжирования, полученные в работах [19], [25].
|
Регион |
Код |
Наш расчет |
Справочно |
||
|
Эффективность за 2009—2022 гг. |
Ранг |
Эффективность РИС |
Индекс |
||
|
1 |
2 |
3 |
4 |
5 |
6 |
|
Ивановская область |
IVA |
0,988 |
1 |
7 |
11 |
|
Костромская область |
KOS |
0,974 |
2 |
3 |
71 |
|
Кемеровская область |
KEM |
0,967 |
3 |
20 |
22 |
|
Республика Марий Эл |
ME |
0,964 |
4 |
15 |
8 |
|
Новосибирская область |
NVS |
0,964 |
5 |
10 |
10 |
|
Томская область |
TOM |
0,963 |
6 |
4 |
1 |
|
Белгородская область |
BEL |
0,960 |
7 |
43 |
19 |
|
Москва |
MOW |
0,960 |
8 |
1 |
6 |
|
Липецкая область |
LIP |
0,959 |
9 |
2 |
59 |
|
Архангельская область |
ARK |
0,959 |
10 |
63 |
49 |
|
Республика Татарстан |
TA |
0,957 |
11 |
17 |
17 |
|
Красноярский край |
KYA |
0,957 |
12 |
39 |
15 |
|
Санкт-Петербург |
SPE |
0,953 |
13 |
5 |
4 |
|
Приморский край |
PRI |
0,953 |
14 |
53 |
23 |
|
Иркутская область |
IRK |
0,953 |
15 |
52 |
21 |
|
Республика Башкортостан |
BA |
0,950 |
16 |
14 |
9 |
|
Свердловская область |
SVE |
0,949 |
17 |
28 |
12 |
|
Волгоградская область |
VGG |
0,946 |
18 |
44 |
67 |
|
Хабаровский край |
KHA |
0,946 |
19 |
48 |
56 |
|
Саратовская область |
SAR |
0,945 |
20 |
41 |
42 |
|
Московская область |
MOS |
0,945 |
21 |
6 |
7 |
|
Ростовская область |
ROS |
0,945 |
22 |
35 |
25 |
|
Республика Дагестан |
DA |
0,942 |
23 |
33 |
60 |
|
Республика Карелия |
KR |
0,942 |
24 |
62 |
30 |
|
Удмуртская Республика |
UD |
0,941 |
25 |
31 |
63 |
|
Вологодская область |
VLG |
0,941 |
26 |
12 |
36 |
|
Пермский край |
PER |
0,941 |
27 |
16 |
18 |
|
Самарская область |
SAM |
0,941 |
28 |
27 |
48 |
|
Тюменская область |
TYU |
0,940 |
29 |
23 |
3 |
|
Чувашская Республика — Чувашия |
CU |
0,940 |
30 |
30 |
61 |
|
Республика Северная Осетия — Алания |
SE |
0,939 |
31 |
22 |
76 |
|
Республика Саха (Якутия) |
SA |
0,939 |
32 |
58 |
54 |
|
Республика Бурятия |
BU |
0,938 |
33 |
64 |
50 |
|
Оренбургская область |
ORE |
0,937 |
34 |
36 |
52 |
|
Ставропольский край |
STA |
0,937 |
35 |
47 |
58 |
|
Карачаево-Черкесская Республика |
KC |
0,937 |
36 |
66 |
62 |
|
Нижегородская область |
NIZ |
0,937 |
37 |
19 |
5 |
|
Алтайский край |
ALT |
0,937 |
38 |
38 |
39 |
|
Челябинская область |
CHE |
0,936 |
39 |
18 |
28 |
|
Кабардино-Балкарская Республика |
KB |
0,936 |
40 |
56 |
66 |
|
Краснодарский край |
KDA |
0,936 |
41 |
9 |
47 |
|
Курская область |
KRS |
0,936 |
42 |
26 |
51 |
|
Омская область |
OMS |
0,935 |
43 |
37 |
16 |
|
Ульяновская область |
ULY |
0,935 |
44 |
11 |
2 |
|
Воронежская область |
VOR |
0,935 |
45 |
8 |
33 |
|
Амурская область |
AMU |
0,934 |
46 |
50 |
73 |
|
Калининградская область |
KGD |
0,934 |
47 |
55 |
38 |
|
Мурманская область |
MUR |
0,934 |
48 |
65 |
53 |
|
Орловская область |
ORL |
0,934 |
49 |
13 |
37 |
|
Ленинградская область |
LEN |
0,933 |
50 |
45 |
57 |
|
Тульская область |
TUL |
0,931 |
51 |
24 |
65 |
|
Республика Коми |
KO |
0,931 |
52 |
61 |
20 |
|
Забайкальский край |
ZAB |
0,930 |
53 |
57 |
72 |
|
Астраханская область |
AST |
0,930 |
54 |
51 |
77 |
|
Новгородская область |
NGR |
0,930 |
55 |
54 |
14 |
|
Тамбовская область |
TAM |
0,930 |
56 |
42 |
79 |
|
Смоленская область |
SMO |
0,929 |
57 |
60 |
34 |
|
Республика Мордовия |
MO |
0,929 |
58 |
59 |
69 |
|
Брянская область |
BRY |
0,929 |
59 |
49 |
32 |
|
Ярославская область |
YAR |
0,928 |
60 |
34 |
26 |
|
Пензенская область |
PNZ |
0,927 |
61 |
40 |
45 |
|
Тверская область |
TVE |
0,924 |
62 |
32 |
27 |
|
Калужская область |
KLU |
0,924 |
63 |
29 |
13 |
|
Камчатский край |
KAM |
0,923 |
64 |
67 |
41 |
|
Владимирская область |
VLA |
0,923 |
65 |
46 |
31 |
|
Курганская область |
KGN |
0,921 |
66 |
25 |
80 |
|
Рязанская область |
RYA |
0,921 |
67 |
21 |
46 |
Примечание: в столбце 5 два последних ранга добавлены из-за разницы в выборках; в столбце 6 ранги имеют пропуски из-за меньшего числа рассматриваемых регионов в нашем исследовании.
Как видно в таблице 2, результаты ранжирования по эффективности довольно сильно отличаются между собой и от столбца 6, где приводится индекс научно-технического потенциала [19, с. 38—39]. Это может свидетельствовать о том, что понятия потенциала и эффективности не имеют сильной связи. Действительно, наличие потенциала еще не означает его эффективной реализации, и наоборот.
На рисунке 3 можно визуально оценить, каким образом формировалась динамика эффективности по периодам. Несмотря на отсутствие явно выраженного тренда, эффективность по периодам держалась в диапазоне 0,9—1,0, что в целом соответствует оригинальному исследованию [22].

Можно заметить, что для значительной группы регионов показатель слабо снижался в первой половине рассматриваемой декады (начало реализации политики стимулирования публикационной активности [37]). В дальнейшем показатель слабо рос. Едва заметное замедление к концу рассматриваемого периода, вероятно, связано с периодом насыщения и исчерпания возможностей экстенсивного наращивания публикационной активности.
Как отмечалось, одной из последних работ по тематике оценки эффективности региональных инновационных систем российских регионов является [25]. Авторы рассмотрели период 1998—2012 гг., который мы затрагиваем лишь частично; также они ориентировались на оценку инновационной и технологической деятельности регионов. Мы же делаем акцент на научно-исследовательской активности. Тем не менее данные сферы тесно связаны, и поэтому результаты могут быть сопоставимы.
В целом мы наблюдаем статистически значимую, но слабую ранговую корреляцию 0,39 с исследованием [25], что, вероятно, обусловлено различиями как в данных, так и в особенностях применяемой методики DEA.
Отметим, что в нашем расчете получается значительно меньший разброс показателей эффективности между регионами: регионы отличаются друг от друга в пределах 10 %, тогда как в цитируемом исследовании между лидером и аутсайдером по эффективности наблюдается многократный разброс значений (более чем в 20 раз). Поскольку мы рассматриваем более ограниченный перечень ресурсов и только немонетарные результаты, небольшое по масштабам различие в эффективности в нашем случае ожидаемо.
Другим важным отличием является то, что в работе [25] Москва лидирует с большим отрывом, фактически задавая стандарт сравнения. По нашим расчетам, Москва не является абсолютным лидером по эффективности, несмотря на значительный прирост публикационной активности в последние годы. Снижение относительной эффективности Москвы в нашем расчете, вероятно, связано с уменьшением ее патентной активности в второй половине десятилетия12, а также с высоким удельным финансированием научно-исследовательского сектора столицы.
Обсуждение и заключение
Мы рассматриваем довольно длинный временной период, что редко встречается в литературе по динамическому DEA. Модель, как и ожидалось, достаточно чувствительна к систематическому занижению ресурсных показателей на уровне данных. Ярким примером является Ивановская область, которая традиционно имеет низкие статистические показатели по ресурсам и попадает на высокие позиции при ранжировании показателей научно-исследовательской деятельности.
Как можно видеть на рисунке 4, регионы, перенасыщенные финансированием научных исследований и разработок, демонстрируют относительно невысокую эффективность. Это Ульяновская область, Самарская, Тюменская области, Красноярский край, для которых характерны высокий уровень ресурсного обеспечения научной деятельности и слабая отдача.
С другой стороны, Томская и Новосибирская области попадают в число лидеров благодаря высоким результатам, хотя для них характерно относительно высокое ресурсное обеспечение. Как отмечалось, в приведенном расчете Москва не является абсолютным лидером (хотя и попадает в первую десятку при ранжировании). Это еще раз подчеркивает то, что эффективность — показатель относительный, и лидерство в абсолютных величинах отнюдь не гарантирует наиболее полного использования выделяемых ресурсов.
Зачастую может наблюдаться даже противоположная ситуация, особенно если в системе распределения активно применяется принцип «от достигнутого». Например, Калининградская область, в динамической модели (в отличие, например, от исследования [24]) получает достаточно низкий ранг эффективности научно-исследовательской деятельности несмотря на сравнительно высокие темпы прироста результативности13. Это можно объяснить как раз эффектом относительно высокого финансирования научно-исследовательского сектора приграничного региона, находящегося в особом геополитическом положении.

Включение в модель переходных переменных в среднем повышает показатели эффективности [22]: распределение показателей получается сопоставимым с теми, которые представлены в оригинальном исследовании по собственной методике и по методике Ч. Kao [18]. Так, в [22] показатели интегральной эффективности всех регионов выше 0,9. В нашем исследовании результаты (показатели технической эффективности) по периодам также варьируются в диапазоне 0,9—1,0.
В целом динамический DEA дает содержательные результаты и удобен в применении. Однако нами была выявлена очень высокая чувствительность модели к логарифмированию показателей (см. также [38]). Кроме того, наблюдается достаточно высокая чувствительность модели к динамике переходной переменной, которая моделируется в форме накопления (в данном случае 5 %-ная доля внутренних затрат на исследования и разработки с учетом 20 %-ной амортизации). Модель гораздо меньше реагирует на переменную качества FWCI с точки зрения общего рейтинга (ее роль скорее состоит в уточнении показателей эффективности).
Можно отметить перспективность применения динамического DEA для оценки и сравнения эффективности научно-исследовательской деятельности регионов. Однако, как всегда, сохраняется рекомендация критически относится к результатам ранжирования регионов и дополнять методику различными аналитическими срезами [19]. В частности, важным выводом исследования является то, что показатели научно-технического потенциала и эффективности его использования могут иметь достаточно слабую связь. Поэтому рейтинги на основе оценок потенциала целесообразно дополнять оценками эффективности, в том числе с помощью DEA.
В качестве перспективных направлений дальнейших исследований мы рассматриваем возможность сравнения и комбинирования результатов различных методов, таких как SFA или индекс сложности, для ранжирования и кластеризации регионов на собранном массиве данных.
Приложение
Программная реализация именно динамических версий DEA, как ни странно, встречается достаточно редко (особенно на фоне большого выбора библиотек, моделирующих статический DEA). В качестве исключения можно отметить библиотеку, созданную на основе [5].
Мы предлагаем короткую реализацию кода для пакета Mathematica, поскольку функциональное программирование и встроенные функции оптимизации, на наш взгляд, хорошо подходят для решаемой задачи.
Данный минимальный код, необходимый для решения задачи, не оптимизирован и не предназначен для масштабирования: его цель скорее в том, чтобы как можно ближе отразить упрощенную схему задачи.
Итак, имея исходные данные, можно ввести несколько переменных:
VARS = {u1, u2, v1, v2, w1, w2};
{U1, U2, V1, V2, W1, W2} = ConstantArray[#, {n, T}] & /@ VARS;
OUT = U1*Y1 + U2*Y2 + W1*Z1T + W2*Z2T;
INS = V1*X1 + V2*X2 + W1*Z1 + W2*Z2;
VARS содержит список символьных переменных (для оптимизации). Остальные строки включают символы, которые обозначают матрицы размера n × T, заполненные символами или данными. U1, U2, V1, V2, W1, W2 заполнены символами u1, u2, v1, v2, w1, w2 соответственно.
Y1, Y2, X1, X2, Z1, Z2, Z1T, Z2T заполнены числовыми значениями (данными).
Подчеркнем, что при формировании матриц OUT и INS оператор «*» означает поэлементное произведение (то есть Hadamard product, а не матричное произведение).
Основная процедура:
NMaximize[
Flatten[{
Part[ (Total /@ OUT), #],
Part[ (Total /@ INS), #] == 1,
Thread[ (Total /@ OUT) <= (Total /@ INS) ],
Thread /@ Thread[OUT <= INS],
Thread[ VARS > 0 ]
}],
VARS] & /@ Range[n]
Коротко прокомментируем процедуру. В Mathematica все выражения содержатся в листах, которые заключаются в фигурные скобки {}. Например, переменная VARS содержит лист символов. Матрица является листом, содержащим несколько других листов (строк). Функции используют квадратные скобки []. Элементы в листах и функциях отделяются друг от друга запятыми.
Запись (Total /@ OUT) в отношении матрицы OUT означает, что происходит суммирование по строкам (по сути, мы применяем функцию Total к каждой строке матрицы — за эту операцию отвечает оператор вида «/@»). Поскольку OUT имеет размер n × T, суммирование по строкам представляет собой суммирование по времени. То же в отношении INS.
Функция Part[], как следует из названия, выделяет часть листа. Например, выражение Part[ {a, b, c}, 2] вернет второе значение «b» из листа {a, b, c}.
Функция Thread[] носит вспомогательный характер, и ее действие можно продемонстрировать на примере выражения Thread[VARS > 0], которое вернет лист неравенств:
{u1 > 0, u2 > 0, v1 > 0, v2 > 0, w1 > 0, w2 > 0}.
По сути, эта функция, как следует из названия, «прошивает» лист с символами, превращая его в лист выражений. Функция Flatten[] убирает лишние скобки и формирует лист с целевой функцией и ограничениями, который понимает процедура численной оптимизации NMaximize.
Наконец, самая главная процедура NMaximize[ … # … ]&/@ Range[n] означает, что нужно провести численную максимизацию по порядку номеров от 1 до n, подставляя соответствующий номер вместо символа #. Символ «#» означает неназванную (pure) переменную (он всегда идет в паре с символом «&»). Конкретные значения, которые следует подставлять вместо #, в данном случае формирует Range[]. Например, Range[4] вернет лист со значениями {1, 2, 3, 4}. Опять же оператор «/@» означает, что эти значения нужно подставлять по одному, а не сразу. Таким образом, мы решаем последовательно n задач оптимизации.
Как обычно, результаты процедуры можно сохранить и работать с ними дальше, но мы опускаем эту часть для краткости изложения. Более подробное изложение можно найти, например, в [39].
Список литературы
Coelli, T., Rao, P., O’Donnel, C., Battese, G. 2005, An introduction to Efficiency and Productivity Analysis. Springer, NY, https://doi.org/10.1007/b136381.
Cook, W., Seiford, L. 2009, Data envelopment analysis (DEA) — thirty years on, European Journal of Operational Research, vol. 192, № 1, p. 1—17, https://doi.org/10.1016/j.ejor.2008.01.032.
Cooper, W. 2013, Data Envelopment Analysis. In: Gass, S. I., Fu, M. C. (eds.), Encyclopedia of Operations Research and Management Science, Springer, Boston, p. 349—358, https://doi.org/10.1007/978-1-4419-1153-7_212.
Kao, C. 2014, Network data envelopment analysis: A review, European Journal of Operational Research, vol. 239, № 1, p. 1—16, http://dx.doi.org/10.1016/j.ejor.2014.02.039.
Lee, D-J., Kim, M-S., Lee, K-W. 2022, A revised dynamic data envelopment analysis model with budget constraints, International Transactions in Operational Research, vol. 29, № 2, p. 1012—1024, https://doi.org/10.1111/itor.12810.
Olesen, O. B., Petersen, N. C. 2016, Stochastic Data Envelopment Analysis — A review, European Journal of Operational Research, vol. 251, № 1, p. 2—21, https://doi.org/10.1016/j.ejor.2015.07.058.
Krivonozhko, V. E., Utkin, O. B., Volodin, A. V., Sablin, I. A. 2002, Interpretation of modelling results in data envelopment analysis, Managerial Finance, vol. 28, № 9, p. 37—47, https://doi.org/doi:10.1108/03074350210768059.
Кривоножко, В. Е., Лычев, А. В. 2010, Анализ деятельности сложных социально-экономических систем, М.: МАКС Пресс, 208 c.
Уткин, О. Б. 2001, Аппарат оценки эффективности функционирования коммерческих банков, Банковские услуги, № 9, с. 16—19.
Гаврилова, А. А., Колмыков, Д. С., Алфеев, А. А. 2006, Многокритериальная оценка эффективности модернизации генерирующего оборудования региональной энергосистемы, Вестник Самарского государственного технического университета. Серия: Технические науки, № 40, с. 155—161.
Лотов, А. В. 2003, Компьютерная визуализация множества производственных возможностей в рамках анализа эффективности производственных единиц, Доклады Академии наук, т. 388, № 2, с. 171—173.
Соловьев, М. Н., Пестриков, С. В. 2008, Разработка математической модели сравнительной оценки эффективности регионов России, Вестник Самарского государственного технического университета. Серия: Физико-математические науки, № 1(16), с. 175—177.
Райнер, Д., Хофманн, П. 2012, Анализ эффективности процессов в цепях поставок, Российский журнал менеджмента, т. 10, № 2, с. 89—116.
Федотов, Ю. В. 2012, Измерение эффективности деятельности организации: особенности метода DEA (анализа свертки данных), Российский журнал менеджмента, т. 10, № 2, с. 51—62.
Матризаев, Б. Д. 2019, Исследование сравнительной эффективности национальной инновационной системы и качества экономического роста на примере сравнительного анализа стран ОЭСР и БРИКС, Вопросы инновационной экономики, т. 9, № 3, с. 673—692, https://doi.org/10.18334/vinec.9.3.40880.
Сазонов, С. Н., Сазонова, Д. Д. 2014, Оценка технической эффективности фермерских хозяйств, Вестник Челябинской государственной агроинженерной академии, т. 69, с. 117— 125.
Федорова, Е. А., Коркмазова, Б. К., Муратов, М. А. 2015, Оценка эффективности компаний с прямыми иностранными инвестициями: отраслевые особенности в РФ, Пространственная экономика, № 2, с. 47—63, https://doi.org/10.14530/se.2015.2.047-063.
Kao, C. 2013, Dynamic data envelopment analysis: A relational analysis, European Journal of Operational Research, vol. 227, № 2, p. 325—330, http://dx.doi.org/10.1016/j.ejor.2012.12.012.
Гохберг, Л. М. (ред.). 2021, Рейтинг инновационного развития субъектов Российской Федерации. Выпуск 7, М.: НИУ ВШЭ, 2021, 274 с.
Lu, W. 2009, The evolution of R&D efficiency and marketability: Evidence from Taiwan’s IC-design Industry, Asian Journal of Technology Innovation, vol. 17, № 2, p. 1—26, https://doi.org/10.1080/19761597.2009.9668671.
Chiu, Y. H., Huang, C. W., Chen, Y. C. 2012, The R&D value-chain efficiency measurement for high-tech industries in China, Asia Pacific Journal of Management, vol. 29, p. 989—1006, https://doi.org/10.1007/s10490-010-9219-3.
Chen, K., Kou, M., Fu, X. 2018, Evaluation of multi-period regional R&D efficiency: An application of dynamic DEA to China’s regional R&D systems, Omega, vol. 74, p. 103—114, https://doi.org/10.1016/j.omega.2017.01.010.
Belgin, O. 2019, Analysing R&D efficiency of Turkish regions using data envelopment analysis, Technology Analysis & Strategic Management, vol. 31, № 11, p. 1341—1352, https://doi.org/10.1080/09537325.2019.1613521.
Firsova, A. A., Chernyshova, G. Y. 2019, Mathematical models for evaluation of the higher education system functions with DEA Approach, Izvestiya of Saratov University. New Series. Series: Mathematics. Mechanics. Informatics, vol. 19, № 3, p. 351—362, https://doi.org/10.18500/1816-9791-2019-19-3-351-362.
Zemtsov, S., Kotsemir, M. 2019, An assessment of regional innovation system efficiency in Russia: the application of the DEA approach, Scientometrics, vol. 120, № 2, p. 375—404, https://doi.org/10.1007/s11192-019-03130-y.
Левитес, Д. Г., Пунанцев, А. А. 2021, Территориальный образовательный сегмент как объект оценки условий функционирования региональных систем образования, Перспективы науки и образования, № 4 (52), с. 577—593, https://doi.org/10.32744/pse.2021.4.38.
28. Ратнер, С. В., Ковалев, А. О. 2021, Методика оценки эффективности региональной системы экологического менеджмента на основе моделей анализа среды функционирования, Экономический анализ: теория и практика, т. 20, № 6, с. 1014—1042, https://doi.org/10.24891/ea.20.6.1014.
Хрусталев, Е. Ю., Ратнер, П. Д. 2015, Оценка экологической эффективности электроэнергетических компаний России на основе методологии анализа среды функционирования, Экономический анализ: теория и практика, № 35 (434), с. 33—42.
Ратнер, С. В., Ковалев, А. О. 2021, Методика оценки эффективности региональной системы экологического менеджмента на основе моделей анализа среды функционирования, Экономический анализ: теория и практика, т. 20, № 6, с. 1014—1042, https://doi.org/10.24891/ea.20.6.1014.
Рослякова, Н. А. 2019, Метод DEA для оценки роли производительности труда в инновационном выпуске регионов СЗФО и Казахстана, Вестник Южно-Российского государственного технического университета (НПИ). Серия: Социально-экономические науки, № 6, с. 67—75, https://doi.org/10.17213/2075-2067-2019-6-67-75.
Покушко, М. В., Ступина, А. А., Медина-Було, И., Дресвянский, Е. С. 2020, Исследование метода анализа среды функционирования и его применение для оценки эффективности предприятий топливно-энергетического комплекса, Вестник Кемеровского государственного университета. Серия: Политические, социологические и экономические науки, т. 5, № 2 (16), с. 251—262, https://doi.org/10.21603/2500-3372-2020-5-2-251-262.
Ратнер, С. В. 2017, Динамические задачи оценки эколого-экономической эффективности регионов на основе базовых моделей анализа среды функционирования, Управление большими системами, № 67, с. 81—106.
Комаревцева, О. О. 2016, Разработка модели эффективного управления изменениями на основе методики DEA в экономических системах муниципальных образований Орловской области, Экономический журнал, № 3 (43), с. 41—58.
Алимханова, А. Н., Мицель, А. А. 2019, Оценка эффективности предприятий на основе метода DEA, Доклады ТУСУР, т. 22, № 2, с. 104—108, https://doi.org/10.21293/1818-0442-2019-22-2-104-108.
Greene, W. 2005, Fixed and Random Effects in Stochastic Frontier Models, Journal of Productivity Analysis, vol. 23, p. 7—32, https://doi.org/10.1007/s11123-004-8545-1.
Fritsch, M., Slavtchev, V. 2007, Universities and innovation in space, Industry and Innovation, vol. 14, № 2, p. 201—218, https://doi.org/10.1080/13662710701253466.
Sivertsen, G., Rousseau, R., Zhang, L. 2019, Measuring scientific contributions with modified fractional counting, Journal of Informetrics, vol. 13, № 2, p. 679—694, https://doi.org/ 10.1016/j.joi.2019.03.010.
Dezhina, I. G. 2017, Science and innovation policy of the Russian government: A variety of instruments with uncertain outcomes?, Public Administration Issues, № 5, p. 7—26, https://doi.org/10.17323/1999-5431-2017-0-5-7-26.
Seiford, L., Zhu, J. 1998, On piecewise loglinear frontiers and log efficiency measures, Computers & Operations Research, vol. 25, № 5, p. 389—395, https://doi.org/10.1016/S0305-0548(97)00078-6.
Saquib, N. 2014, Mathematica for Data Visualization, Packt Publishing.

{kind=link}